


Abstract
Within the past two years, 90 percent of the world’s data has been created. Sharing personal data daily online, such as communication, pictures and opinions, has become the new normal. This global level of comfort with sharing data has impacted the way in which a consumer interacts with financial institutions. With increased data sharing tendencies of consumers comes greater responsibility from intuitions to store and use the data received ethically and compliantly. Another noted trend among consumers over the past decade, is choosing trusted firms over the cheaper options. This review highlights how financial services institutions can build trust with their consumers through their choice and design of data mining techniques and illustrates two specific applications. Building a trusted brand has been proven to increase an entity’s competitive edge and so, in the midst of a global slow down, trust has become a more relevant strategy to retain and attain financial customers.
Introduction
The financial industry (banking, fintech and big tech) has enjoyed an incline of success since the 2008 global recession. This rise has not been devoid of scandal and considering the industry’s cyclical nature, this time of prosperity is widely predicted to end, or at least slow, in the coming financial year. Newspaper headlines are consistently littered with cautionary tales of financial data breaches and defiling of unsuspecting users’ trust. We are still in an age however, where financial services customers are more willing than ever to share data, so long as their data is used to personalise offerings and technology to their needs (Accenture, 2019). The profile of consumers is changing also, along with users’ level of comfort with technology. 74 percent of millennials are willing to share personal data with banks versus 49 percent of those 55 and over (Desjardins, 2019).
The aim of this review is to explore how financial services businesses can build and maintain consumer trust through the data mining techniques chosen and mining applications. Trust is as, if not more, important than cost to consumers (Kim, Xu, and Gupta, 2012). Considering this, the emphasis on a financial firm’s Corporate Social Performance (CSP) strategy and methods of increasing its CSP will be highlighted during this review (Pivato, Misani, and Tencati, 2008). It has been shown that CSP influences consumer trust which subsequently impacts a consumer’s actions and ultimate provider choice (Pivato, Misani, and Tencati, 2008). In a bottom-line motivated industry, the monetary advantages of using a CSP as strategy north-star must be emphasized.
Brand equity is a term globally synonymous with acceptance of premium prices by consumers. It has been shown that brand trust is one of the main strategies to infer brand equity and reinforce customer loyalty (Delgado-Ballester and Munuera-Alemán, 2005). To ensure global brand equity as a relational, market-based asset, companies in every industry must build brand trust (Delgado-Ballester and Munuera-Alemán, 2005). The hypothesis of this review is that a brand can build trust through the data mining techniques chosen and can continue to propagate trust through chosen technique applications.
Techniques
Data mining utilises some machine learning techniques that enable machines to learn from their own performance which helps facilitate prediction of trends and discovery of unknown patterns in a given dataset (Chitra and Subashini, 2013). The underlying algorithms and techniques being used to mine data have ultimately not changed since the late twentieth century, but the level of data, purposes, motivations and boundless application potentials of mining techniques have increased exponentially (Berry and Linoff, 2004). An assumption being operated under for the purpose of this paper is that preserving privacy builds trust with consumers. In the following subsections, methods of data mining that preserve privacy as well as a framework to be used to ensure responsible data science will be highlighted.
a. Methods to ensure anonymity
There are a variety of functions required from data mining algorithms in the financial sector: classification, regression, attribute importance, association, clustering, feature extraction and anomaly detection (Chitra and Subashini, 2013). These functions can be further separated into two categories: supervised and unsupervised learning functions (Chitra and Subashini, 2013). Prior to choosing any one of these functions to apply to a banking scenario, there are a few criteria of the technique to be considered to be privacy-preserving. Clifton et al (2002) highlight these criteria, which include secure multiparty computation, obscuring data, the introduction of “need to know” basis, protection from disclosure, and anonymity. As detailed in the introduction, financial firms have quite unadulterated access to an overwhelming amount of data on each of their customers. Due to this, to ensure privacy for each user, anonymity is seen as the key trust builder (Chitra and Subashini, 2013). Clifton et al (2002) propose the following definition of individual privacy which preserves k-anonymity aspects while protecting against individual identification:
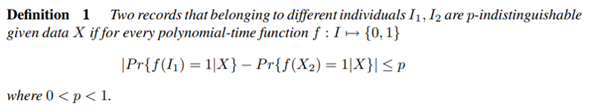
To highlight the most trustworthy data mining methods, i.e. the methods that preserve privacy best in any given application scenario, an analysis of all relevant advantages and disadvantages of each method must be considered. Aideen et al., conducted such a review and concluded that classification established on “distortion, association rule, hide association rule, taxonomy, clustering, associative classification, outsourced data mining, distributed, and k-anonymity” have all been shown to preserve privacy, albeit to some extent (Aideen et al., 2015). Anonymity has been called out as a key privacy-preserving data mining technique (Aideen et al., 2015).
As the financial sector is transaction-based, item-set mining could be employed, as proposed by Shrivastava et al. (2011), which would result in increased distortion of customer profiles for identification. Item-set mining tunes two probability parameters, nfp and fp, for a minor trade-off in efficiency for privacy. In the Aideen et al. (2015) review, out of the various algorithms reviewed, the item-set mining proves optimal on the condition that the “fraction of frequent items among all the available items is less”. Privacy-preserving data mining should be implemented in various fields to ensure further optimizing of security and efficiency (Aideen et al., 2015).
b. RDS Standards Framework
Responsible Data Science (RDS) practices can be illustrated by a firm caring more about how data is handled, stored and processed over all-else (van der Aalst, 2016). RDS can create a standard whereby end-users can instinctively trust a firm’s data mining application as they know the impact on them, and their data, has been considered throughout the mining process (van der Aalst, 2016). By consistently and continuously having the consumer and their needs at the top of the agenda, financial businesses can impact the consumer’s provider choice. By paying heed to the challenges specific to mining customer data outlined by van der Aalst (2016), financial services firms can ensure Fairness, Accuracy, Confidentiality, and Transparency (FACT) for all of their customers and attain/maintain a trusted status (Figure 1) (van der Aalst, 2016).
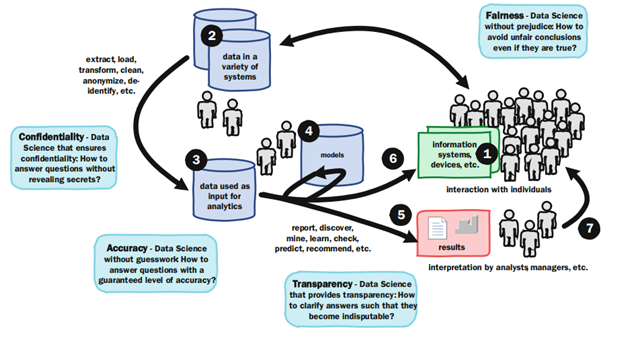
Figure 1: Data Science Pipeline (van der Aalst, 2016)
Ensuring compliance with international standards for data processing, such as General Data Protection Regulation (GDPR), is a requirement of RDS and can also help infer trust in techniques for consumers (van der Aalst, 2016). Considering the RDS methodology and the results of its implementation outlined by van der Aalst (2016), if financial services firms were to aim for full compliance of the FACT concept under the RDS methodology it can only be assumed that customers could trust a firm’s data-mining practices. External factors, such as the introduction of legislation like GDPR, will only continue to increase ownership and accountability of institutions that hold customer data (Aideen et al., 2015). Trust will, therefore, continue to be a reliable commodity for financial firms to trade on.
Applications
There are a variety of applications for data mining in the financial sector including customer retention, automatic credit card approval, potential fraud detection, and credit score rating assignment. Using privacy-preserving techniques, as highlighted in section 2, consumers can continue to be assured that their data was collected fairly, they are treated equally, and their privacy is protected.
To decide which applications are best suited to a financial firm and their customers’, analysis of customer profiles should be executed (Accenture, 2019). A transparent search for data mining applications or ensuring offerings are equal to, if not better than, competitors is a method a building a trusted reputation that retains and can assist with attaining customers (Delgado-Ballester and Munuera-Alemán, 2005). Demonstration of an ability to apply new technologies well and quickly is very popular among tech-savvy customers (Accenture, 2019). Two major applications of data mining in the financial industry that will be explored further are protected against fraud and the creation of objective credit scores.
Protection against fraud
Creating reliable fraud protection has been identified as a factor that would increase 36 percent of surveyed consumers’ trust in a financial service company (Desjardins, 2019). The incentive for banking institutions to prevent fraud rather than retrospectively detect fraud has never been higher considering global legislation trends continuing to require refunds for “blameless victims” by banks (Meadows, 2019). Fraud protection is a knowledge-intensive activity as the mining system must find deviations to the deemed normal patterns of a customers’ transactions (Ngai et al., 2011). To detect a fraudulent transaction, a clustering technique would be used so similar “normal” transactions can be grouped. The clustering algorithm would run across all the transactions for a particular customer account and a clustering label would be assigned for each observation, for example, December transactions may be increased due to expenses associated with Christmas for any given account. Using other datapoints like the geo-location of the transactions, time of day or frequency of transactions, fraud could be detected and successfully prevented (Ngai et al., 2011). Decision trees, logistic model, Bayesian belief network, probability and neural networks are among other commonly used techniques in industry to detect and classify fraudulent transactions (Ngai et al., 2011).
Some techniques can be used for certain applications but are not suited for others. For example, probability, specifically probability density estimation method, analyses the “density” of a customer’s past behaviour (Ngai et al., 2011). A customer’s transactions from the last k days would be surveyed and proportions of the estimation would be maximised to maximise the likelihood of the transaction being true or fraudulent (Ngai et al., 2011). This technique requires too much interaction with a billing system to be used in real-time for instantaneous transaction review (Ngai et al., 2011).
Preventing fraud monetarily benefits the customer and the financial institution. Fraud detection has many other applications in finance and other industries too. To build and maintain trust, communication of an instance of fraud prevention to the associated customer would benefit a financial firm’s reputation, i.e. show the new technology is working (Accenture, 2019). Follow up investigation of how an account could have been compromised or what led to the attempted fraudulent transaction would benefit other customers and that firm’s brand on ability to prevent further fraud (Ngai et al., 2011).
b. Objective Credit Score Rating and Loan review
Assigning a credit score rating to loan candidates, whether they are an organisation or an individual consumer, is a prudent method of risk assessment that financial institutions globally complete (Siami and Hajimohammadi, 2013). Siami and Hajimohammadi (2013) outline four categories of scoring that are used by financial firms to consider a loan application:
- Application credit scoring: if the applicant is a new customer to the firm, and no transactional history can be attained for the applicant, the application form contents holds most bearing on the success of the loan.
- Behavioural scoring: if the applicant is an existing customer, the institution can review their past transaction history, current account balance, a record of loan repayments, etc.
- Collection scoring: customers are grouped by their level of insolvency and the level of attention that will be required while processing the application
- Fraud detection: applications are ranked based on the probability of inclusion of fraudulent information by an applicant
Using data mining as a technique to create credit scores is growing in popularity in the financial industry (Siami and Hajimohammadi, 2013). There are increased examples of rule extraction techniques specific to data mining, such as, neural networks, decision trees and rule-based classifiers being applied to credit application forms. Post-review of a variety of literature sources, and only considering single, non-hybrid techniques, Support Vector Machine (SVM) classification achieved the best results for creation of credit scores and objective review of loan applications (Huang et al., 2007; Siami and Hajimohammadi, 2013). Relatively few input features can be used, and an identical clarificatory accuracy can be achieved with SVM classification (Huang et al., 2007). When considering hybrid models, there is a lack of general research completed on the topic as there is an unavailability of credit score data widely available to model a solution (Siami and Hajimohammadi, 2013). This being stated however, experimental results have shown that a Gaussian – SVM hybrid has a promising future as a data mining technique for credit score creation (Huang et al., 2007).
The explicit nature of the application form and the chosen technique’s output, i.e. the application is either accepted or rejected, is easy logic for anyone to understand (Siami and Hajimohammadi, 2013). This contrasts with other data mining technique outputs which are more subjective (Siami and Hajimohammadi, 2013). Due to the sensitive nature of any given reason and the data required to apply for a loan, an objective method of application review ensures the financial institutions and customers’ interests are both met. Financial businesses are logic-driven, as is their policymaking, and so the effective rule design that is enabled with data mining enables further objective thinking applications (Siami and Hajimohammadi, 2013).
Conclusion
Customers want a financial institution to be invested in their financial success (Accenture, 2019). This review has demonstrated that a financial firm can create a personable brand, one which can be trusted, through the utilisation of the right data mining techniques. The recommended path to becoming a trusted financial brand is as follows:
- Using data mining techniques that preserve user privacy. This technique signals to consumers they are appreciated as individuals as their identity means that much.
- Implementing frameworks like Responsible Data Science. Using or creating standards of accountability create a benchmark that customers can easily test a financial provider against. Having such metrics would encourage ownership in the financial industry.
- For fraud prevention, it is recommended to use clustering. For new customers, until there are enough transactions to cluster for profile building, it can be more difficult to prevent fraud. It is recommended that a variety of data points are used and learnings from alternate fraud preventions for other customers are applied too. Communication of this care to customers would instantiate a more favourable brand for a given financial firm.
- For the creation of credit scores and review of loan applications objectively it is recommended to use SVM. In the coming years, further research may be completed in this area but technique choice should never compromise the objectivity of the output.
A
financial firm communicating that it is taking steps to operate more
transparently with its customers on how they are using data creates a better
brand image as a Corporate Social Performer (Pivato, Misani, and Tencati,
2008). A firm that can make statements like this and live up to the standards,
such as RDS, they hold themselves accountable to, is a brand that could be
worthy of trust (van der Aalst, 2016). Trust
will continue to grow as a reliable commodity for financial firms to trade on
as long as consumers continue to share their data.
References
Accenture. (2019). Discover the Patterns in Personality. Available: https://www.accenture.com/_acnmedia/pdf-95/accenture-2019-global-financial-services-consumer-study.pdf. Last accessed 10/10/2019.
Aldeen, Y.A.A.S., Salleh, M. and Razzaque, M.A., 2015. A comprehensive review on privacy preserving data mining. SpringerPlus, 4(1), p.694.
Berry, M.J. and Linoff, G.S., 2004. Data mining techniques: for marketing, sales, and customer relationship management. John Wiley & Sons.
Clifton, C., Kantarcioglu, M. and Vaidya, J., 2002, November. Defining privacy for data mining. In National science foundation workshop on next generation data mining (Vol. 1, No. 26, p. 1).
Chitra, K. and Subashini, B., 2013. Data mining techniques and its applications in banking sector. International Journal of Emerging Technology and Advanced Engineering, 3(8), pp.219-226.
Delgado-Ballester, E. and Luis Munuera-Alemán, J., 2005. Does brand trust matter to brand equity? Journal of product & brand management, 14(3), pp.187-196.
Meadows, S. (2019). Blameless fraud victims to be refunded by banks from May. Available: https://www.telegraph.co.uk/money/consumer-affairs/blameless-fraud-victims-refunded-banks-may/. Last accessed 11/10/2019.
Huang, C.L., Chen, M.C. and Wang, C.J., 2007. Credit scoring with a data mining approach based on support vector machines. Expert systems with applications, 33(4), pp.847-856.
Jeff Desjardins. (2019). Visualizing the Importance of Trust to the Banking Industry. Available: https://www.visualcapitalist.com/trust-banking-industry/ . Last accessed 10/10/2019.
Kim, H.W., Xu, Y. and Gupta, S., 2012. Which is more important in Internet shopping, perceived price or trust? Electronic Commerce Research and Applications, 11(3), pp.241-252.
Ngai, E.W., Hu, Y., Wong, Y.H., Chen, Y. and Sun, X., 2011. The application of data mining techniques in financial fraud detection: A classification framework and an academic review of literature. Decision support systems, 50(3), pp.559-569.
Pivato, S., Misani, N. and Tencati, A., 2008. The impact of corporate social responsibility on consumer trust: the case of organic food. Business ethics: A European review, 17(1), pp.3-12.
Shrivastava R, Awasthy R, Solanki B (2011) New improved algorithm for mining privacy—preserving frequent item sets. Int J Comp Sci Inform 1:1–7
Siami, M. and Hajimohammadi, Z., 2013. Credit scoring in banks and financial institutions via data mining techniques: A literature review. Journal of AI and Data Mining, 1(2), pp.119-129.
van der Aalst, W.M., 2016, April. Responsible data science: using event data in a “people friendly” manner. In International Conference on Enterprise Information Systems (pp. 3-28). Springer, Cham.
hi, your style is perfect.Following your news.